
Selected Inversion
GPU-Accelerated Parallel Algorithms for Structured Sparse Matrices
Matrix A (sparse)

Few spatial locations
Matrix B (denser)

More spatial locations
Selected Inverse

Same dense arrowhead!
Same dense arrowhead!
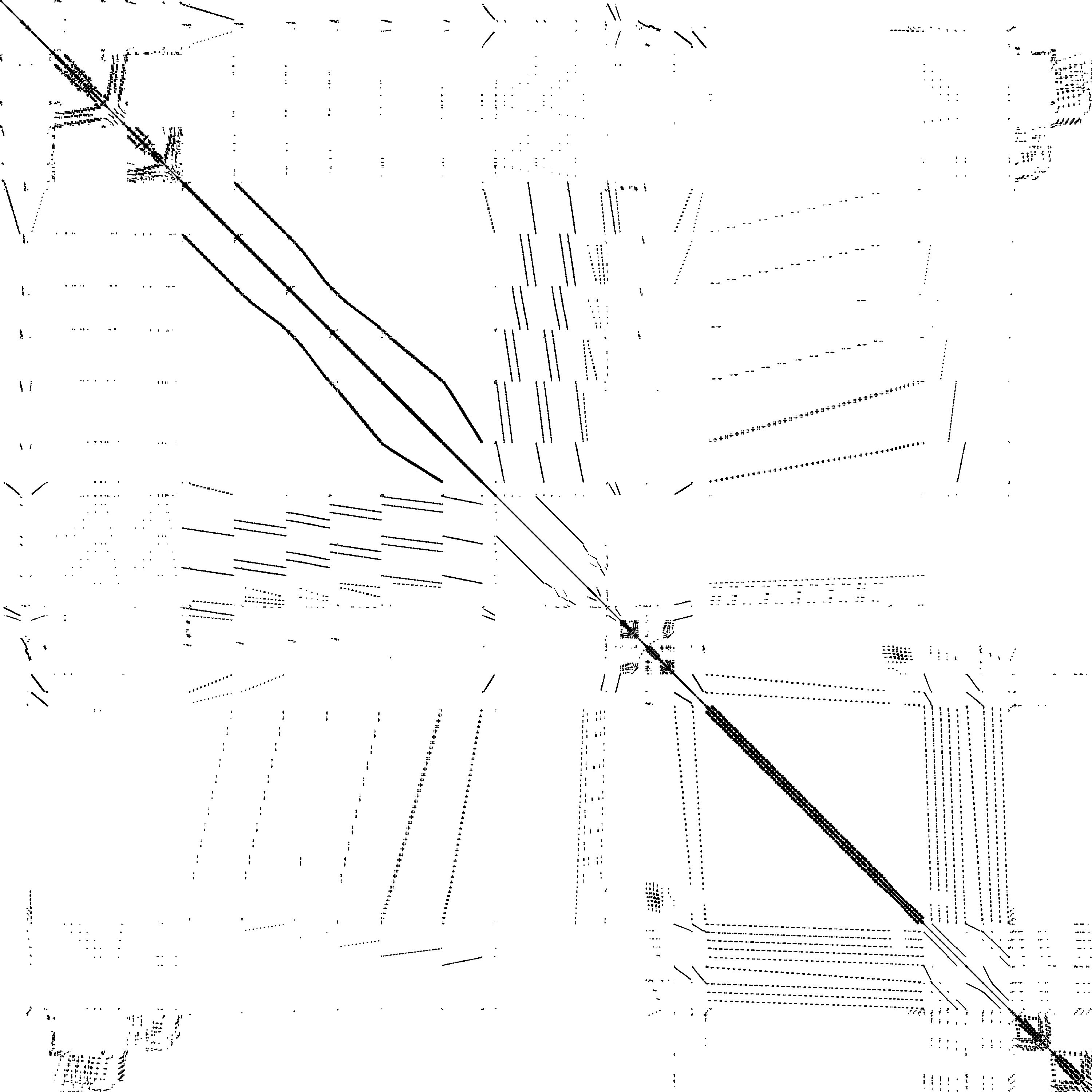
Key Observation
Regardless of initial sparsity, the selected inverse retains the arrowhead structure. This enables efficient tile-based computation.
Why Arrowhead Structure?
Arrowhead matrices arise from Kronecker products modeling space-time dependencies:
- Spatio-temporal models
- Gaussian Markov Random Fields
- Hierarchical Bayesian models
Real Applications
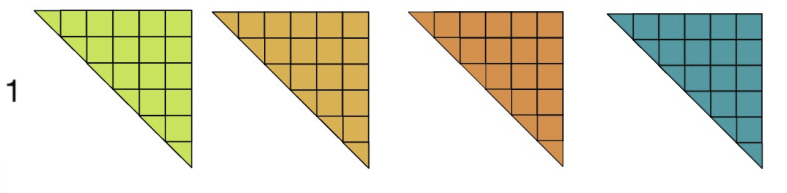 full → full
full → full
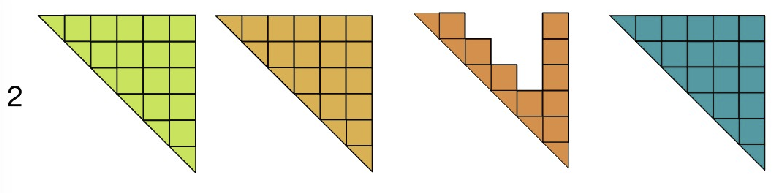 diag → full!
diag → full!
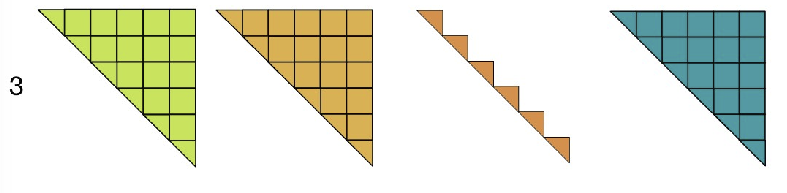 diag+ → full!
diag+ → full!
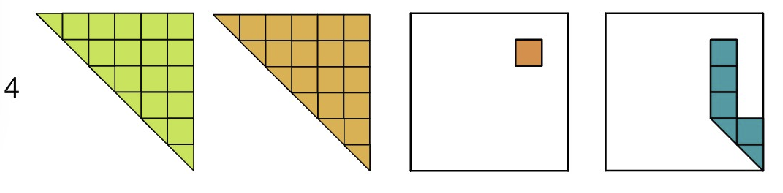 off-diag → min
off-diag → min
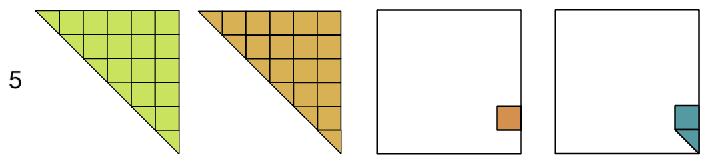 corner → min
corner → min
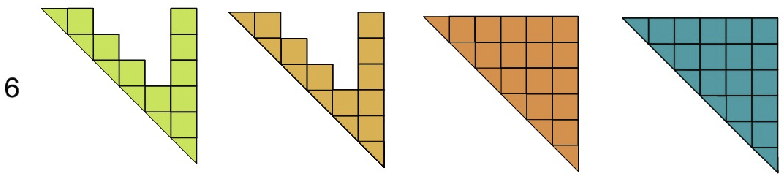 full → full
full → full
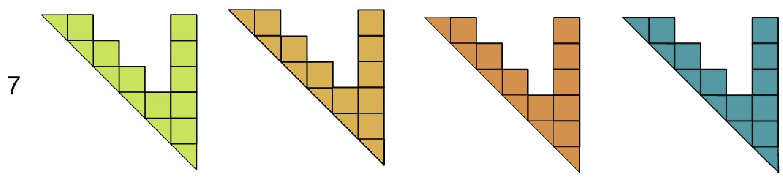 arrow → arrow! ★
arrow → arrow! ★
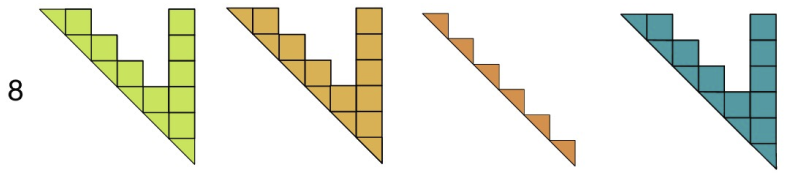 partial → partial
partial → partial
 off-diag → min
off-diag → min
 corner → min
corner → min
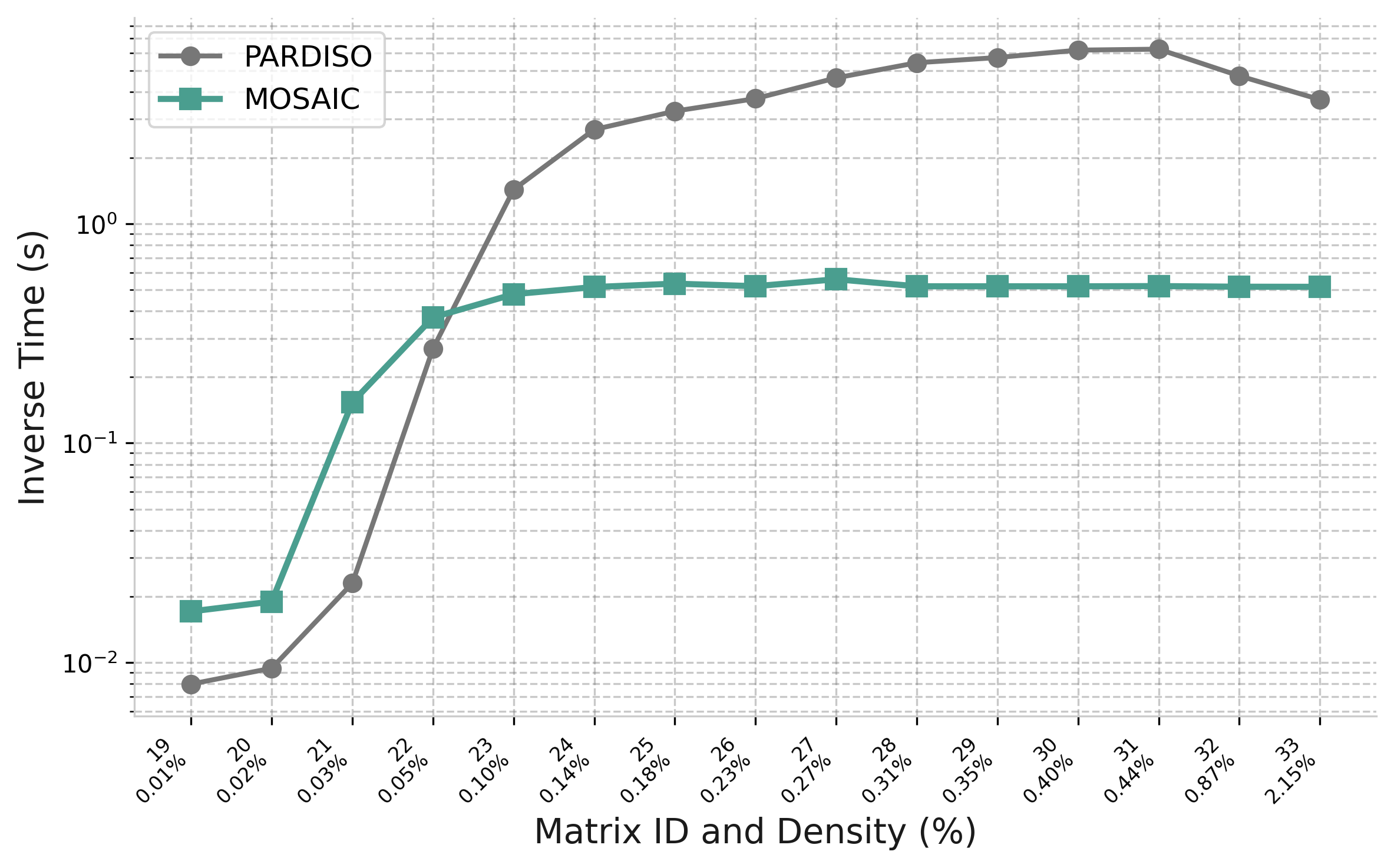
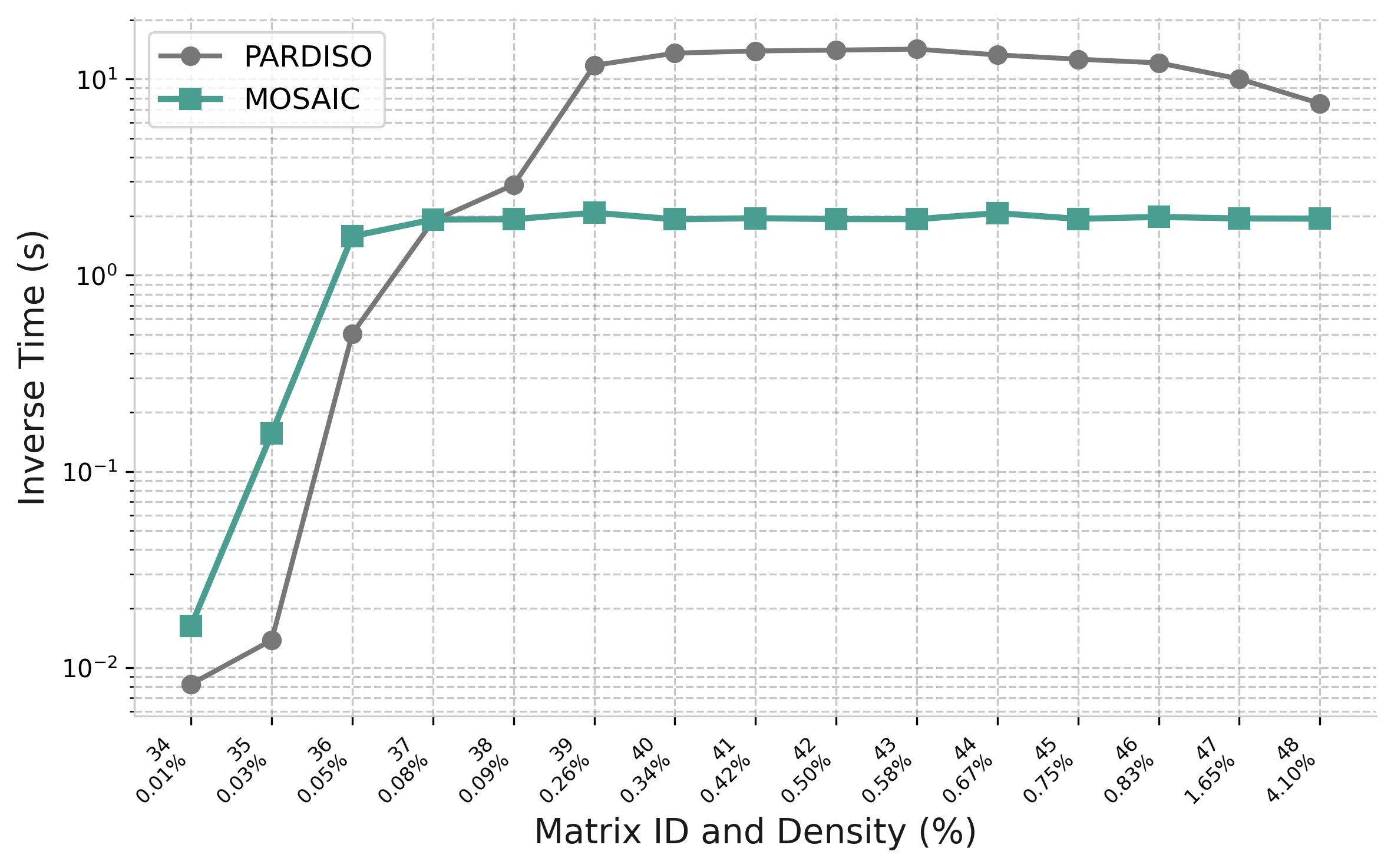
Goal: compute A−1ij for all (i,j) in the sparsity pattern of A, not just a few entries
Non-zeros of A
(before fill-in)
→
compute A−1ij
at every (i,j)
where Aij ≠ 0
Selected entries of A−1
(same sparsity pattern)
MUMPS
Solves A·x = eᵢ per entry via elimination tree pruning. Efficient for few arbitrary entries, not for computing the full sparsity pattern.
Amestoy et al., SIAM J. Matrix Anal. Appl., 2001
PSelInv (PEXSI)
Supernodal left-looking selected inversion. Slower than PARDISO on large structured problems, with out-of-memory failures. PEXSI is not actively maintained.
Jacquelin et al., ACM TOMS, 2017 | Verbosio, PhD thesis, 2019
Serinv
Specialized for block-tridiagonal + arrowhead matrices only. sTiles targets general sparse SPD matrices beyond this fixed structure.
Maillou et al., arXiv:2503.17528, 2025
Panua-PARDISO ✓ chosen benchmark
State-of-the-art supernodal LLT solver, strongest competitor for full-pattern selected inversion.
Schenk et al., Future Gener. Comput. Syst., 2001 | Schenk & Gärtner, Parallel Comput., 2002
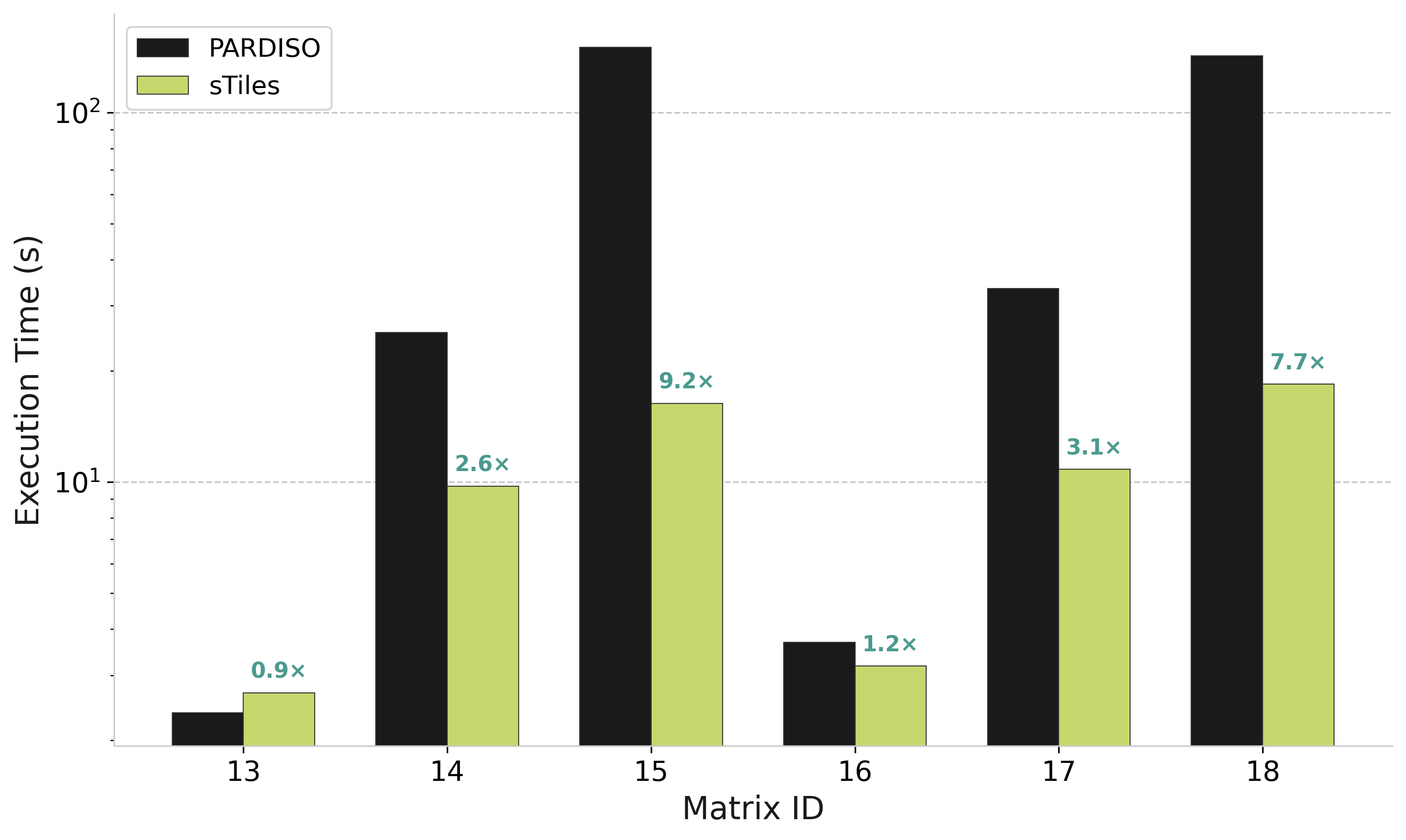
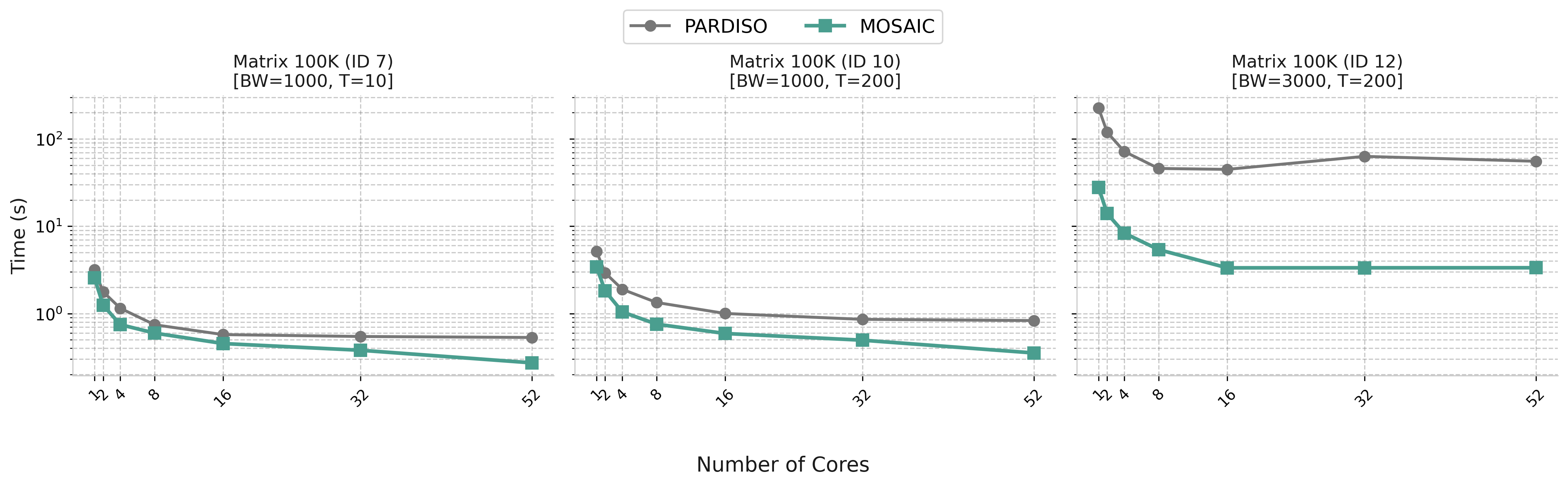
sTiles vs PARDISO for selected inversion on 500K matrices (computing (A⁻¹)ᵢⱼ on sparsity pattern)
sTiles vs PARDISO
SelInv / Chol time ratio
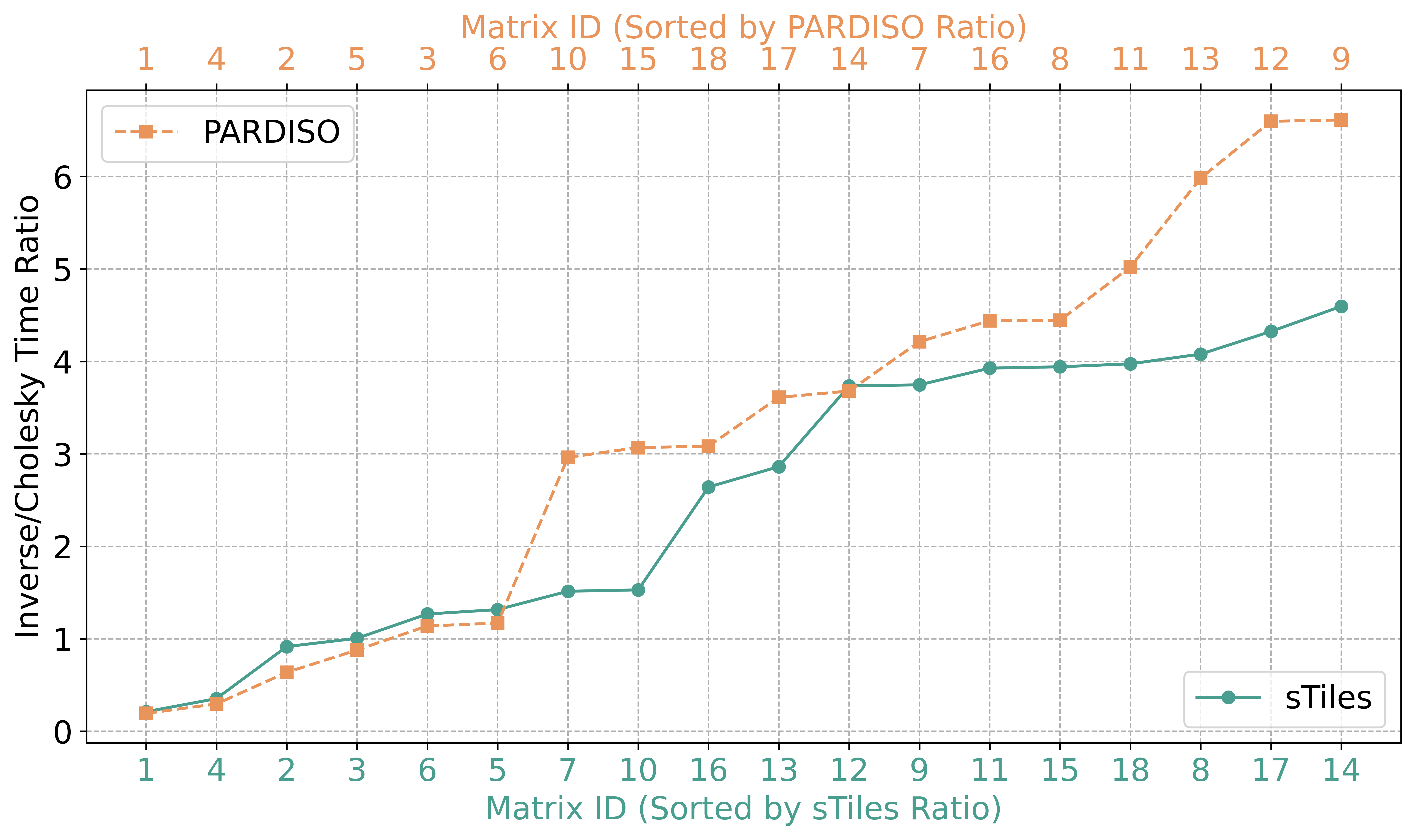
Reference: PARDISO Selected Inversion [Schenk et al., SIAM SISC 2007]
Key Observation
Matrix ID 12 (high bandwidth): 16× speedup at 52 cores. sTiles scales consistently while PARDISO saturates early.
Bandwidth 1500
Bandwidth 3000
ship_001
n = 34,920 | nnz = 3,896,496
| # | P-Chol | P-SelInv | S-Chol | S-SelInv |
|---|---|---|---|---|
| 1 | 0.393 | 0.906 | 0.591 | 0.897 |
| 8 | 0.080 | 0.278 | 0.104 | 0.270 |
| 16 | 0.077 | 0.289 | 0.077 | 0.295 |
| 32 | 0.064 | 0.358 | 0.089 | 0.326 |
| 50 | 0.079 | 0.284 | 0.088 | 0.357 |

nd6k
n = 18,000 | nnz = 6,897,316
| # | P-Chol | P-SelInv | S-Chol | S-SelInv |
|---|---|---|---|---|
| 1 | 5.335 | 10.500 | 3.479 | 6.360 |
| 8 | 0.849 | 6.354 | 0.540 | 1.273 |
| 16 | 0.550 | 5.642 | 0.351 | 0.934 |
| 32 | 0.483 | 4.972 | 0.409 | 1.271 |
| 50 | 0.552 | 4.124 | 0.456 | 1.320 |
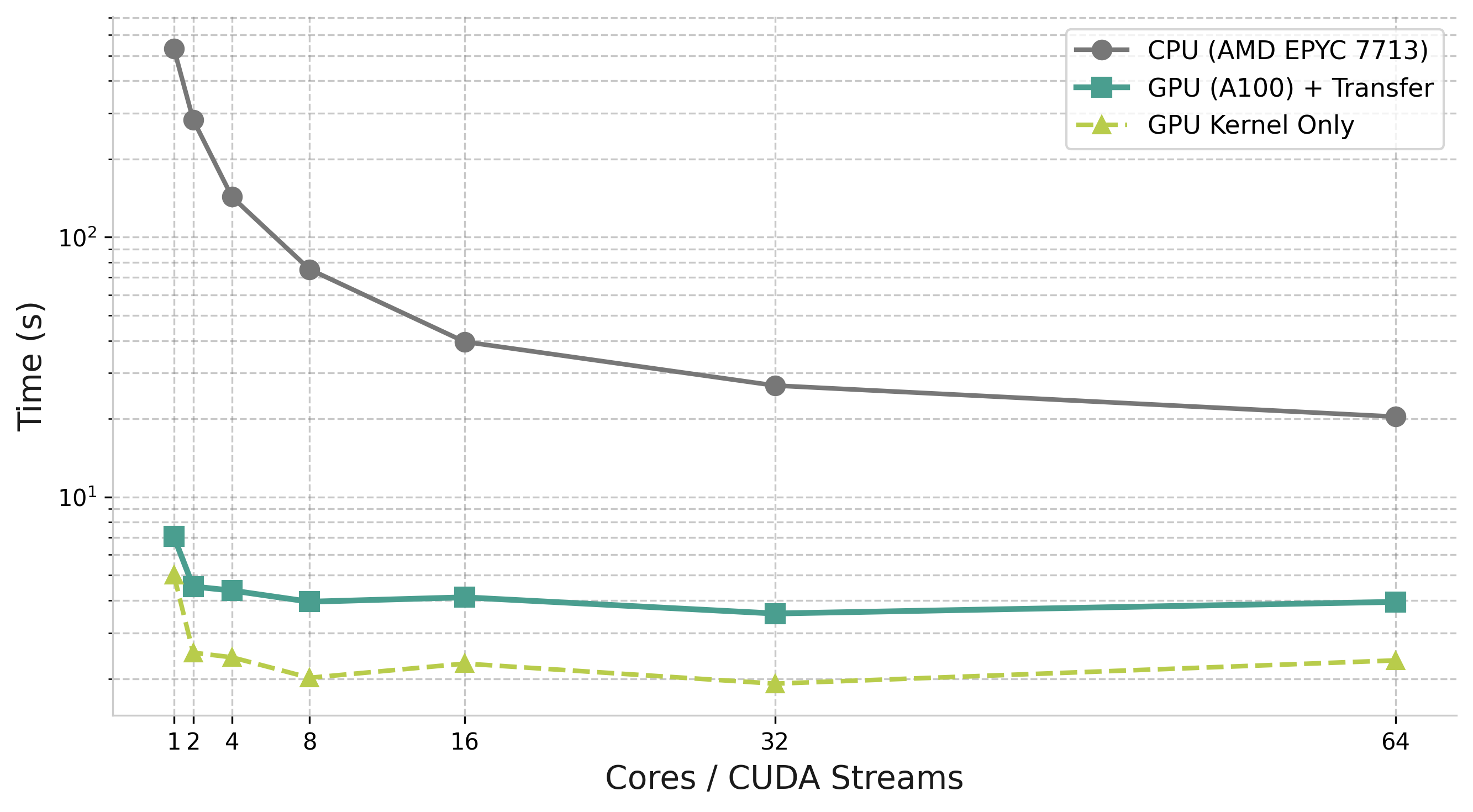
GPU Implementation
- Tile size 600 (vs 120 on CPU)
- cuBLAS/cuSOLVER kernels
- CUDA streams per host thread
Trade-off
Large tiles maximize kernel throughput but reduce task parallelism.
Thank You
Questions?